Batch Streaming and Job Execution
| Mule runtime engine version 3.8 reached its End of Life on November 16, 2021. For more information, contact your Customer Success Manager to determine how to migrate to the latest Mule version. |
Enterprise, CloudHub
Anypoint Studio comes bundled with the ability to stream batch processing and configure the order of batch job execution.
Streaming Batch Commits
Mule offers the ability to process fixed-size groups of records – say, upserting 100 records at a time from a CSV file to Salesforce. Mule also supports streaming commits, which enables you to batch process all the records in the job instance, no matter how many or how large. For example, if you need to write millions of records from Salesforce to a CSV file, you can process the records as a streaming batch commit.
Instead of a list of elements that you receive with a fixed-size batch commit, the streaming functionality – an iterator – ensures that you receive all the records in a batch job without running out of memory. By combining streaming batch commit and DataMapper streaming in a flow, you can transform large datasets in one single operation and one single write to disk. The example below illustrates the actions Mule takes to batch process streaming data.
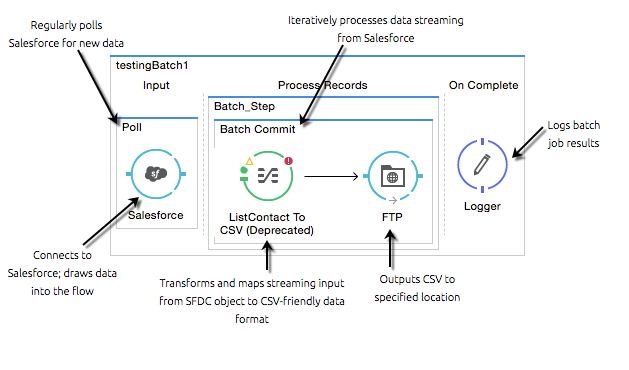
|
To enable your application to batch process streaming data, configure both the batch commit and the DataMapper to enable streaming. |
|
In general, you probably don’t use batch streaming when sending data through an Anypoint Connector to a SaaS provider, like Salesforce, because SaaS providers often have restrictions on accepting streaming input. Rather, use streaming batch processing when writing to a file such as CSV, JSON, or XML. |
Batch Commit Element
In the Properties Editor of Batch Commit element, click the checkbox to enable Streaming.
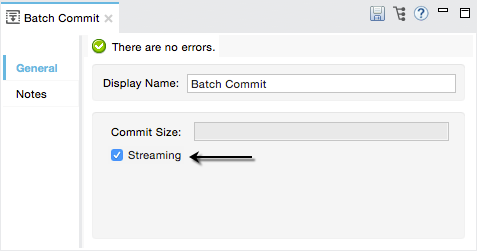
<batch:commit streaming="true" doc:name="Batch Commit">DataMapper Element
In the Mapping Editor of the DataMapper element, click the mapping icon, then select Configuration.
<data-mapper:transform config-ref="listcontact_to_csv" doc:name="List<Contact> To CSV" stream="true"/>
In the Configuration Properties Editor, click the checkbox to enable Streaming.
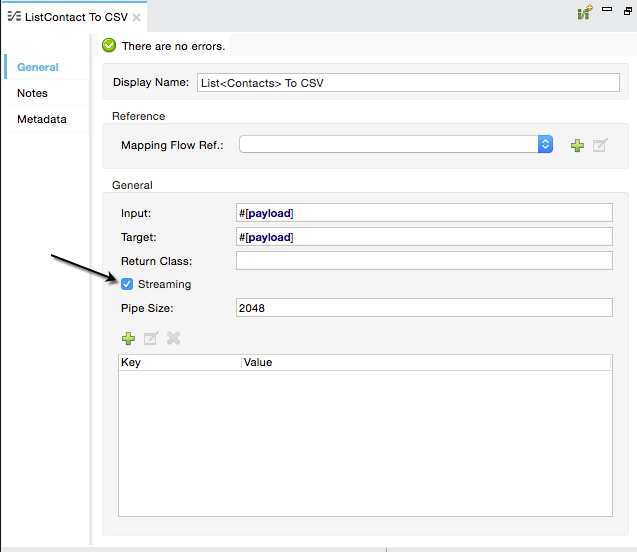
|
Batch-processing streaming data affects the performance of your application, slowing the pace at which it processes transactions. Though performance slows, the trade-off of being able to batch-process streaming data may warrant using it in your implementation. |
Ordering Batch Job Execution
To account for situations in which different batch jobs may be competing for resources, you can adjust the configuration of the Batch’s Scheduling Strategy. For example, if one batch job instance is dependent upon another’s completion, you can set the scheduling strategy to sequentially process the batch job instances according to the order they were created. Where non-sequential processing of batch jobs could cause problems in data consistency, be sure to set the scheduling strategy to process them sequentially.
The following sections describe how the configuration of this attribute instructs Mule how to submit batch job instances to a target resource.
Ordered Sequential Attribute
Value of scheduling-strategy attribute:
`ORDERED_SEQUENTIAL (Default) `
Mule executes batch job instances sequentially, according to the order in which Mule created them.
If Mule creates a job instance at 12:00:00 and then creates another at 12:00:01, Mule does not execute the second instance until the first one leaves the executable state.
Note: As this value is the default, the XML config does not explicitly display the configuration.
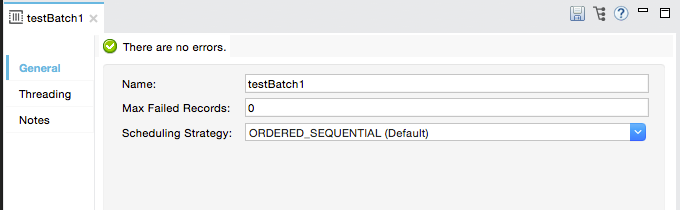
<batch:job name="testBatch1" >Round Robin Attribute
Value of scheduling-strategy attribute:
ROUND_ROBIN
Mule executes batch job instance according to a random, round robin pattern. a| image::round-robin.png[round_robin]
<batch:job name="testBatch1" scheduling-strategy="ROUND_ROBIN">| If your application uses more than one batch job, you must individually define the scheduling strategy of each. Mule configures scheduling strategy at the batch job level, meaning that a ROUND_ROBIN or ORDERED_SEQUENTIAL configuration only applies to instances of the same batch job. |
Tips
-
Streaming from SaaS providers: In general, you likely wouldn’t use batch streaming when sending data through an Anypoint Connector TO a SaaS provider, like Salesforce, because SaaS providers often have restrictions on accepting streaming input. Rather, use streaming batch processing when writing to a file such as CSV, JSON, or XML.
-
Batch streaming and performance: Batch processing streaming data does affect the performance of your application, slowing the pace at which it processes transactions. Though performance slows, the trade-off to be able to batch process streaming data may warrant using it in your implementation.
-
Batch streaming and access to items: The biggest drawback to using batch streaming is that you have limited access to the items in the output. In other words, with a fixed-size commit, you get an unmodifiable list, thus allowing you to access and iteratively process its items; with streaming commit, you get a one-read, forward-only iterator.
-
Setting multiple scheduling strategies: Setting all your application’s batch jobs’ scheduling strategies to ORDERED_SEQUENTIAL does not ensure that job instances created in one batch job respect the order in which job instances were created in a separate batch job. Setting the scheduling strategy only enforces the order in which Mule processes instances of the same job.
Complete Code Example
Studio Visual Editor
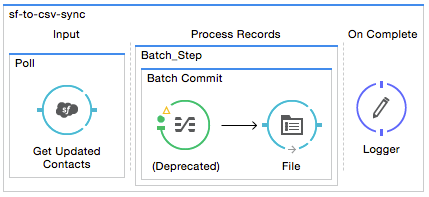
XML Editor or Standalone
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:context="http://www.springframework.org/schema/context" xmlns:file="http://www.mulesoft.org/schema/mule/file"
xmlns:batch="http://www.mulesoft.org/schema/mule/batch" xmlns:data-mapper="http://www.mulesoft.org/schema/mule/ee/data-mapper" xmlns:sfdc="http://www.mulesoft.org/schema/mule/sfdc" xmlns="http://www.mulesoft.org/schema/mule/core" xmlns:doc="http://www.mulesoft.org/schema/mule/documentation"
xmlns:spring="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.mulesoft.org/schema/mule/file http://www.mulesoft.org/schema/mule/file/current/mule-file.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-current.xsd
http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/batch http://www.mulesoft.org/schema/mule/batch/current/mule-batch.xsd
http://www.mulesoft.org/schema/mule/ee/data-mapper http://www.mulesoft.org/schema/mule/ee/data-mapper/current/mule-data-mapper.xsd
http://www.mulesoft.org/schema/mule/sfdc http://www.mulesoft.org/schema/mule/sfdc/current/mule-sfdc.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-current.xsd">
<sfdc:config name="Salesforce56" username="${sfdc.username}" password="${sfdc.password}" securityToken="${sfdc.securityToken}" url="${sfdc.url}" doc:name="Salesforce">
<sfdc:connection-pooling-profile initialisationPolicy="INITIALISE_ONE" exhaustedAction="WHEN_EXHAUSTED_GROW"/>
</sfdc:config>
<data-mapper:config name="listcontact_to_csv" transformationGraphPath="list<contact>_to_csv.grf" doc:name="listcontact_to_csv"/>
<context:property-placeholder location="mule-app.properties"/>
<batch:job name="sf-to-csv-sync" max-failed-records="-1" >
<batch:threading-profile poolExhaustedAction="WAIT" />
<batch:input>
<poll doc:name="Poll">
<fixed-frequency-scheduler frequency="10" startDelay="20" timeUnit="MINUTES"/>
<watermark variable="nextSync" default-expression="2014-01-01T00:00:00.000Z"
doc:name="Get Next Sync Time" selector="MAX" selector-expression="#[payload.LastModifiedDate]"/>
<sfdc:query config-ref="Salesforce56" query="dsql:SELECT Email,FirstName,Id,LastModifiedDate,LastName FROM Contact WHERE CreatedDate >= #[flowVars['nextSync']] ORDER BY LastModifiedDate ASC" doc:name="Get Updated Contacts"/>
</poll>
</batch:input>
<batch:process-records>
<batch:step name="toCSV">
<batch:commit streaming="true" doc:name="Batch Commit">
<data-mapper:transform config-ref="listcontact_to_csv" stream="true" doc:name="List<Contact> To CSV"/>
<file:outbound-endpoint outputPattern="contacts.csv" path="/Users/marianogonzalez/Desktop" responseTimeout="10000" doc:name="File" />
</batch:commit>
</batch:step>
</batch:process-records>
<batch:on-complete>
<logger level="WARN" message="Total Records Loaded: #[message.payload.getLoadedRecords()], Failed Records: #[message.payload.getFailedRecords()], Processing time: #[message.payload.getElapsedTimeInMillis()]" doc:name="Logger"/>
</batch:on-complete>
</batch:job>
</mule>See Also
-
Access the full documentation for Batch Processing for the latest general availability release of Mule.
-
For more information on best design-time practices with DataSense and DataMapper, consult the DataSense documentation.