Choosing the Right Clustering Topology
| Mule runtime engine version 3.8 reached its End of Life on November 16, 2021. For more information, contact your Customer Success Manager to determine how to migrate to the latest Mule version. |
You can deploy Mule in many different topologies. As you build your Mule application, it is important to think critically about how best to architect your application to achieve the desired availability, fault tolerance, and performance characteristics. This page outlines some of the solutions for achieving the right blend of these characteristics through clustering. There is no one correct approach for everyone, and designing your system is both an art and a science. If you need more assistance, MuleSoft Professional Services can help you by reviewing your architecture plan or designing it for you. For more information, contact us.
About Clustering
Deploying an application into a cluster is useful for achieving the following:
-
High availability (HA): making your system continually available in the event that one or more servers in the cluster, or a data center, fails.
-
Fault tolerance (FT): ensuring recovery from failure of an underlying component. Typically, the recovery is achieved through transaction rollback or compensating actions.
-
Scaling: ensuring that your application can scale horizontally to meet increased demand.
This page describes several possible clustering solutions.
Mule High Availability
Enterprise Edition
Mule High Availability provides basic failover capability for Mule. When the primary Mule instance become unavailable (e.g., because of a fatal JVM or hardware failure or it’s taken offline for maintenance), a backup Mule instance immediately becomes the primary node and resumes processing where the failed instance left off. After a system administrator has recovered the failed Mule instance and brought it back online, it automatically becomes the backup node. Seamless failover is made possible by a distributed memory store that shares all transient state information among clustered Mule instances, such as:
Mule High Availability is currently available for the following transports:
|
|
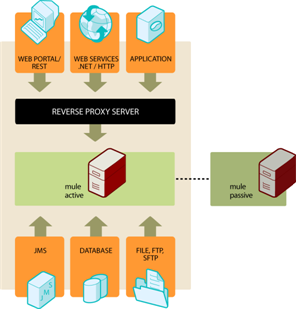
Mule High Availability is available with Mule Enterprise subscriptions. For details including technical highlights, requirements, and installation details, contact us.
JMS Queues
JMS can be used to achieve HA & FT by routing messages through JMS queues. In this case, each message is routed through a JMS queue whenever it moves from component to component.
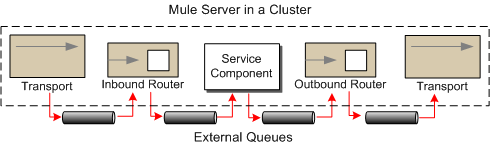
Pros:
-
Easy to do
-
Well understood by developers
Cons:
-
Requires lots of transactions, and transactions can be complicated
-
Performance hit if you’re using XA
Load Balancers
Load balancers simply route requests to different servers based on the the current load of each server and which servers are currently up. Load balancers can be software or hardware based. This approach is commonly used with clustered databases (see below).
Pros:
-
Straightforward to do
-
Well understood by developers
Cons:
-
Not a complete solution on its own, doesn’t provide fault tolerance.
Example
In this example architecture, HTTP requests come in through a load balancer and are immediately put on a JMS queue. The JMS queue is clustered between the different servers. A server will start processing a message off the JMS queue and wrap everything in a transaction.
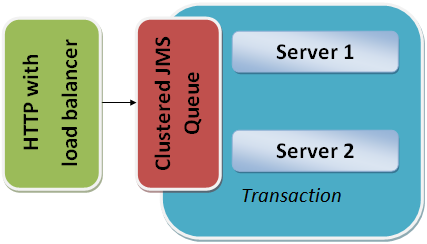
If the server goes down, the transaction will roll back and another server will pick up the message and start processing it.
Note: If the HTTP connection is open for the duration of this process, this approach will not work, as the load balancer will not transparently switch connections between servers. In this case, the HTTP client will need to retry the request.
Maintaining State in a Database
If you have a clustered database, one option for your application is to simply store all state in the database and rely on it to replicate the data consistently across servers.
Pros:
-
Straightforward to do
-
Well understood by developers
Cons:
-
Not all state is amenable to being stored in the database
Handling Stateful Components
While most applications can be supported by the above techniques, some require sharing state between JVMs more deeply.
One common example of this is an aggregator component. For example, assume you have an aggregator that is aggregating messages from two different producers. Producer #1 sends a message to the aggregator, which receives it and holds it in memory until Producer #2 sends a message.
Producer #1 ---> |----------|
|Aggregator| --> Some other component
Producer #2 ---> |----------|If the server with the aggregator goes down between Producer #1 sending a message and Producer #2 sending a message, Producer #2 can’t just send its message to a different server because that server will not have the message from Producer #1.
The solution to this is to share the state of the aggregator component across different machines through clustering software such as Terracotta, Tangosol Coherence, JGroups, etc. By using one of these tools, Producer #2 can simply fail over to a different server. Note that MuleSoft has not tested Mule with these tools and does not officially support them.
Pros:
-
Works for all clustering cases
-
Can work as a cache as well
Cons:
-
Not officially supported by MuleSoft
-
Requires performance tuning to get things working efficiently