Runtime Fabric Architecture
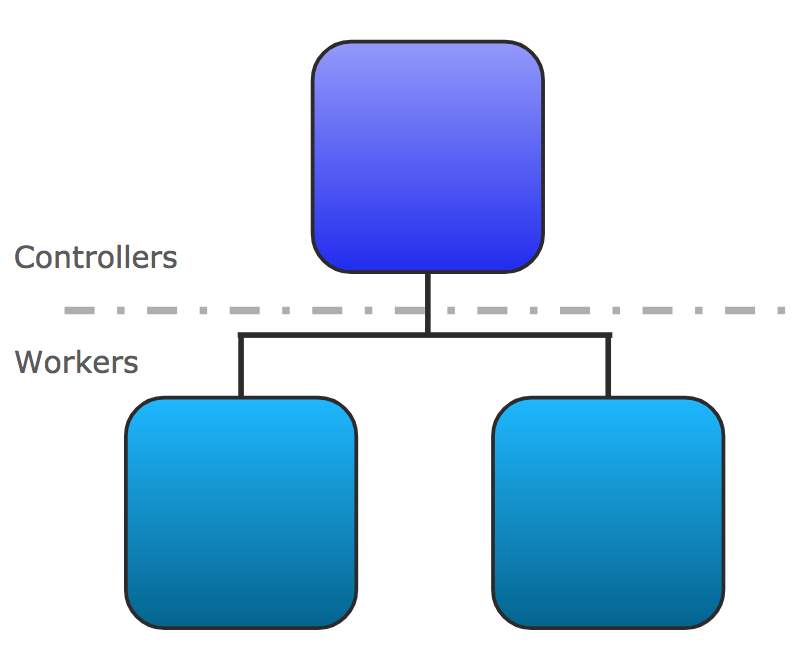
Anypoint Runtime Fabric is composed of a set of VMs that form a cluster. Each VM serves as either a controller node or a worker node.
-
Controller: a VM dedicated for operating Runtime Fabric, including orchestration services, a distributed database, load balancing, and services that enable you to manage the cluster from Anypoint Platform.
-
Worker: a VM dedicated for running Mule applications and API gateways. Mule applications and API proxies run on workers.
This separation of responsibilities enables scaling of the worker nodes based on the number of Mule applications. It also enables scaling the controller nodes based on the frequency of deployments, changes in application state, and amount of inbound traffic. To ensure resources are available to re-schedule and re-deploy applications in the event of a hardware failure, MuleSoft recommends over-provisioning the number of worker nodes.
By default, the services operating Runtime Fabric are deployed across the controller nodes to avoid a single point of failure in the system.
Anypoint Runtime Fabric uses a set of technologies, including Docker and Kubernetes, which are tuned to operate well with Mule runtimes. Knowledge of these technologies is not required to deploy or manage Mules on Runtime Fabric. Managing Runtime Fabric requires the operational and infrastructure-level experience needed to support any system at scale. We recommend following best practices and running fire drill scenarios in controlled environments to help prepare for unexpected failures.
| Deployments of applications and gateways not powered by Mule on Anypoint Runtime Fabric is not supported. |
Development and Production Configurations
Anypoint Runtime Fabric supports development and production configurations. These supported configurations specify the minimum nodes and resources required.
Development Configuration
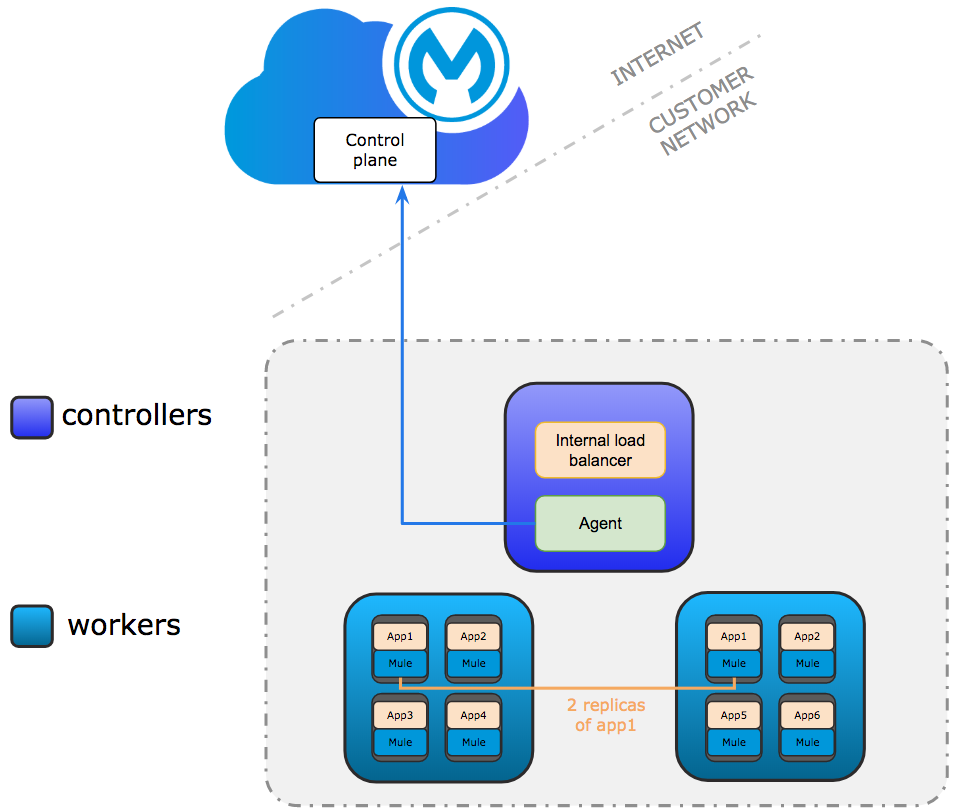
The development configuration is intended for testing only. It requires at least one controller and two worker nodes. The controller node runs the internal load balancer and agents used to connect to Anypoint Platform. Communication between the agent and Anypoint Platform is always outbound. Multiple replicas of application can run across workers.
Production Configuration
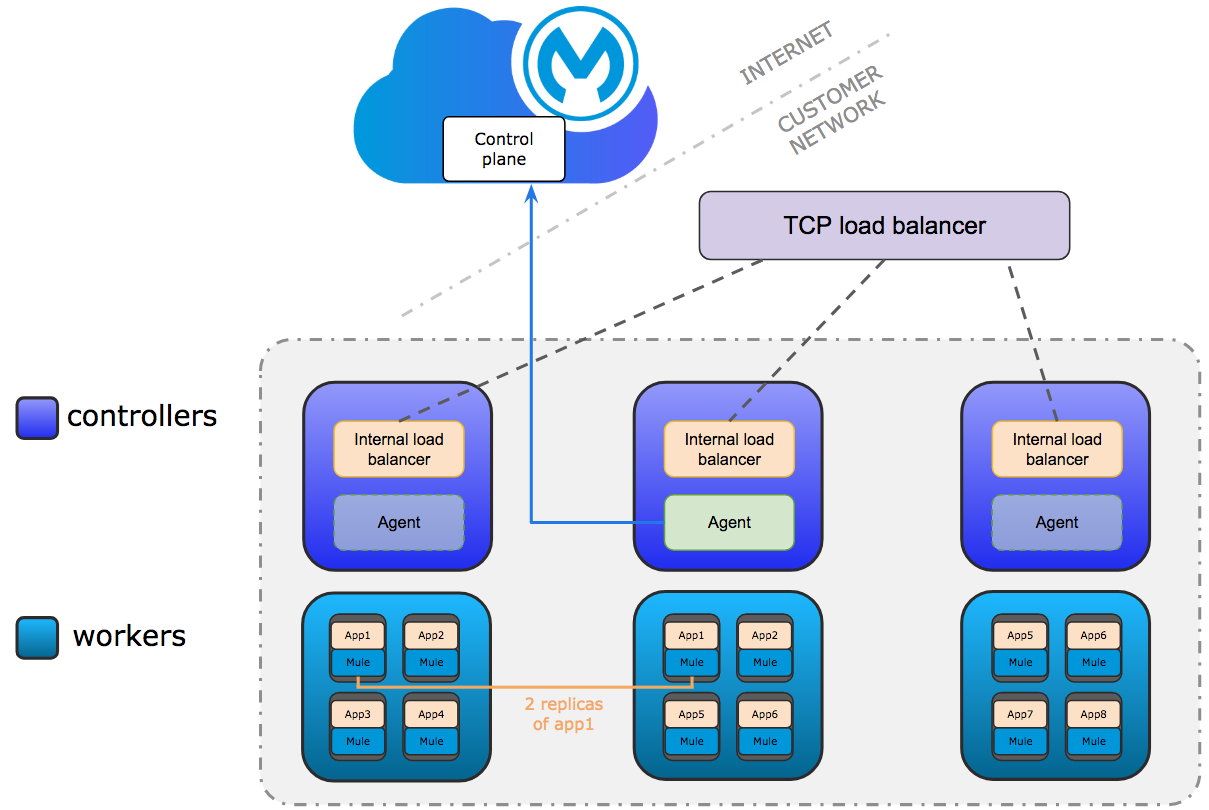
Only controllers run the internal load balancer and agents used to connect to Anypoint Platform.
Agents can run on any controller. Agent communication is always outbound.
The minimum requirements are 3 controller and 3 worker nodes. 3 controllers enable a fault-tolerance of losing 1 controller. To improve fault-tolerance to lose 2 controllers, a total of 5 controllers should be configured.
Mule applications run on workers. Multiple replicas of applications can run across workers.
Scaling Considerations
-
Minimum required number of controller nodes
-
Production environment: 3
-
Non-production environment: 1
-
-
The maximum number of supported controller nodes is 5.
| An odd number of controller nodes is required for fault tolerance. |
+ Consider scaling the number of controller nodes in the following situations:
-
Fault tolerance is needed to mitigate the impact of controller node hardware failure.
-
Production traffic is being served with applications running on Runtime Fabric.
-
CPU/Memory required for controller nodes
-
The default (and required minimum) is 2 cores with 8 GiB memory each. You must consider the amount of resources needed for the internal load balancer when sizing controller nodes. For additional information, refer to Internal Load Balancer resource allocation.
-
-
Required number of worker nodes. The maximum number of worker nodes supported is 16.
-
Production environment: 3
-
Non-production environment: 2
-
-
| Plan to overprovision with one extra worker node for fault-tolerance and for applying upgrades to avoid downtime for applications. |
-
CPU/memory required for worker nodes
-
The default (and required minimum) is 2 cores with 15 GiB memory each. You must consider how many Mules and tokenizers you plan to run on Runtime Fabric, and what they are licensed to deploy. Plan on approximately 0.5 cores per worker node for overhead. Refer to Hardware Requirements for additional information.
-
Network Architecture
The following diagram shows the general network architecture of Runtime Fabric.
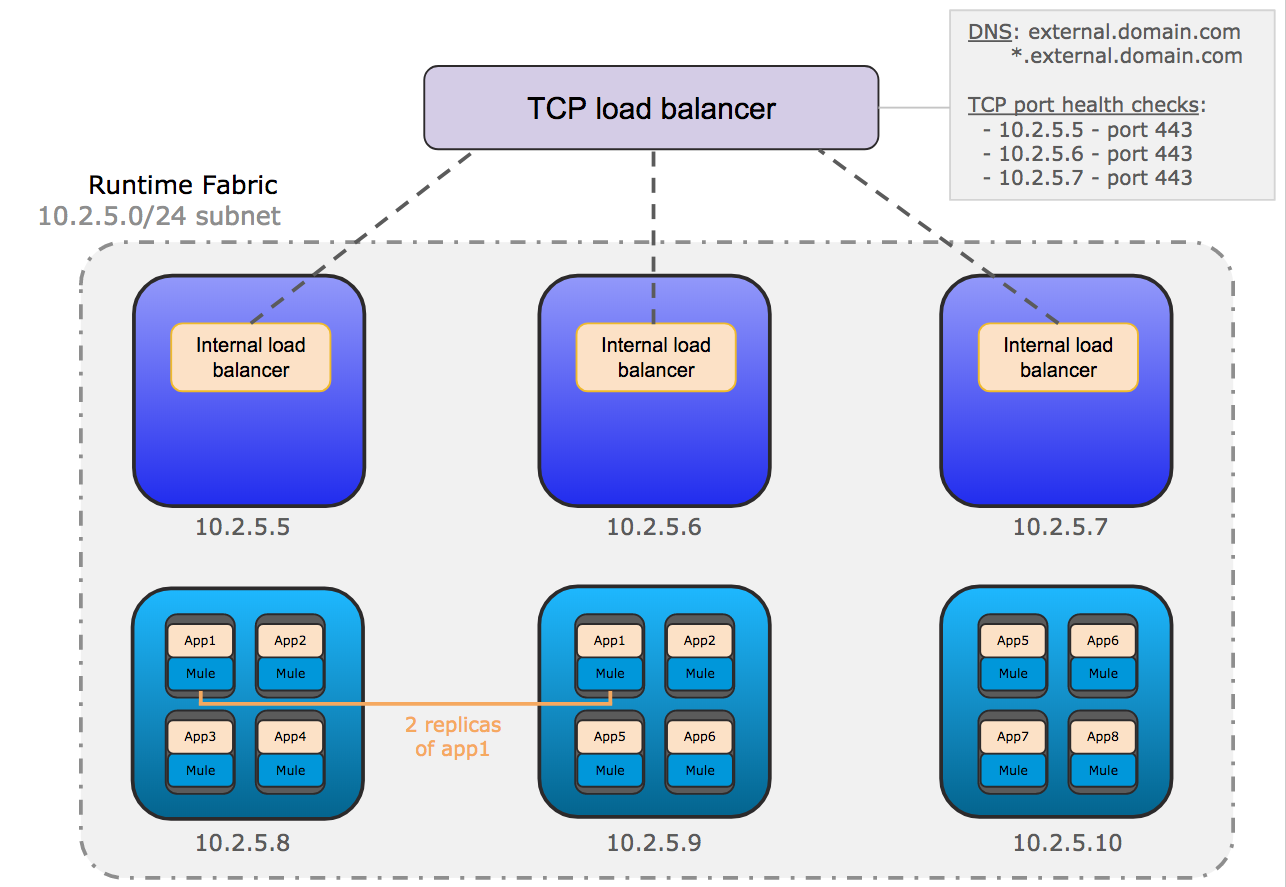
This diagram shows the TCP load balancer used to load balance requests across the internal load balancers running on the controllers. It also shows the internal load balancer that distributes requests to each replica of Mule applications running on the workers.
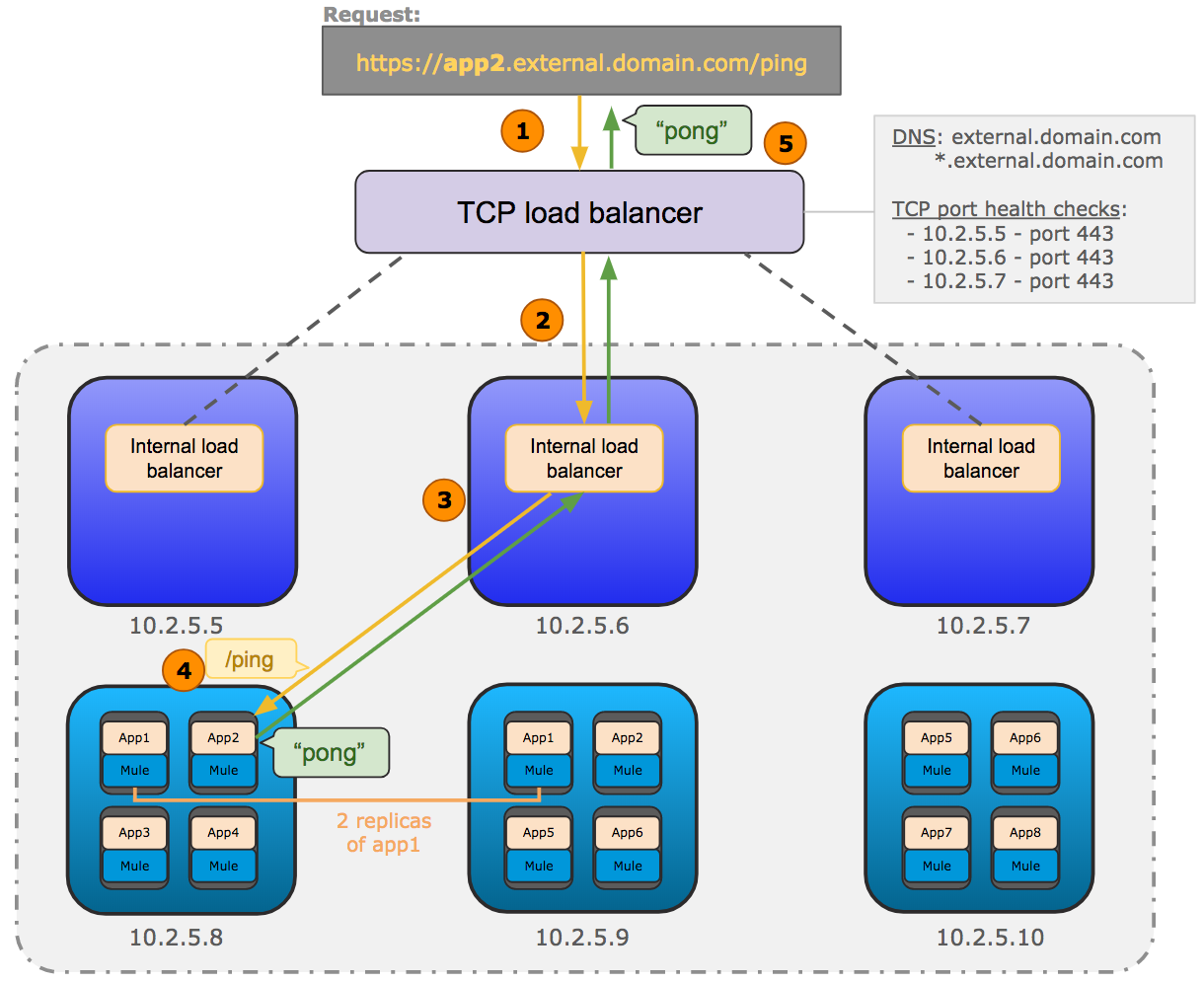
-
The incoming HTTP request is forwarded to the external TCP load balancer.
-
The TCP load balancer forwards the request to an available internal load balancer on Runtime Fabric.
-
The internal load balancer decrypts the request and directs it to an available replica of the Mule application (app2) in the diagram above.
-
The application sends a response which is routed back to the requester.
Installer Life-Cycle
It is important to allocate the infrastructure based on the documented system requirements to ensure reliable operation of Runtime Fabric. The installation process fails if the minimum requirements have not been met.
The default behavior of the AWS and Azure provisioning scripts creates a set of virtual machines and disks defined by the minimum requirements. It also creates a private network with the required network ports configured. This is optimal when evaluating Runtime Fabric before integrating within your primary network. You should consult with your network administrator to determine if the default behavior is compatible. You may need to modify the provisioning scripts to accommodate your organization’s requirements.
The disks required to run Anypoint Runtime Fabric are used for the following:
-
Each controller VM requires a minimum of 60 GiB dedicated disk with at least 3000 IOPS to run the etcd distributed database.
-
This disk is referred to as the
etcddevice.
-
-
Each controller and worker VM requires a minimum of 100 GiB (for development) or 250 GiB (for production) dedicated disk with at least 1000 IOPS for Docker overlay and other internal services.
-
This disk is referred to as the
dockerdevice.
-
| See Verify System Requirements for Anypoint Runtime Fabric before beginning the installation. |
During installation, the installation package is downloaded to a controller VM that serves as the leader of the installation.
Anypoint Runtime Fabric is configured to run as a cluster across multiple virtual machines. Each VM acts as one of two roles:
-
Controller VMs are dedicated to operate and run Runtime Fabric services. The internal load balancer also runs within these VMs.
-
Worker VMs are dedicated to run Mule applications.
One controller VM acts as a leader during the installation. This VM downloads the installer and makes it accessible to each other VM on port 32009. Other VMs copy the installer files from the leader, perform the installation, and join the leader to form a cluster.
During the installation, a set of pre-flight checks run to verify the minimum hardware, operating system, and network requirements for Runtime Fabric as defined. If these requirements are not met, the installer will fail.
The installation process combines the following steps:
-
For AWS and Azure, provision infrastructure per the system requirements.
-
Install Runtime Fabric across the VMs.
-
Activate Runtime Fabric with your Anypoint organization.
-
Install your organization’s Mule Enterprise license.
To complete these steps, specify environment variables for each VM at the beginning of installation. The leader requires additional variables to activate and add the Mule license. A script runs on each VM to perform the following actions:
-
Format and mount each dedicated disk
-
Add mount entries for each disk to
/etc/fstab -
Add iptable rules
-
Enable required kernel modules
-
Start the installation
On the controller VM acting as the leader for installation, the following are performed:
-
Run the activation script after installation
-
Run the Mule license insertion script after registration