Mule High Availability (HA) Cluster Overview
A cluster is a set of Mule instances that acts as a unit. In other words, a cluster is a virtual server composed of multiple nodes. The servers in a cluster communicate and share information through a distributed shared memory grid. This means that the data is replicated across memory in different physical machines.
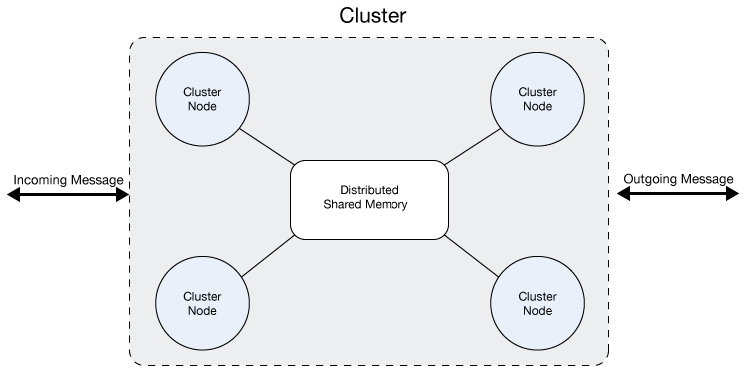
The Benefits of Clustering
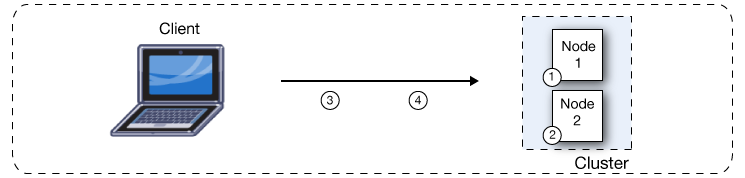
Clustering together Mule ESB servers ensures high system availability. If a node becomes unavailable due to failure or planned downtime, another node in the cluster can assume the workload and continue to process existing events and messages. The following figure illustrates the processing of incoming messages by a cluster of two nodes. Notice that the processing load is balanced across nodes – Node 1 processes message 1 while Node 2 simultaneously processes message 2.
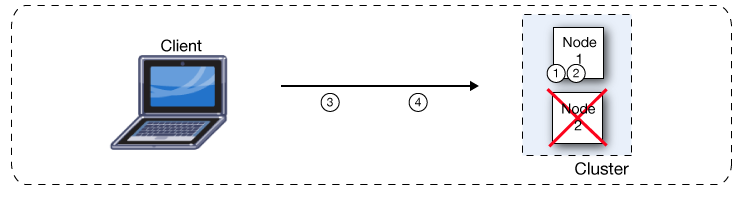
If one node fails, the other available nodes pick up the work of the failing node. As shown in the following figure, if Node 2 fails, Node 1 processes both message 1 and message 2.
Because, all nodes in a cluster process messages simultaneously, clusters can also improve performance and scalability. Compared to a single node instance, clusters can support more users or improve application performance by sharing the workload across multiple nodes or by adding nodes to the cluster.
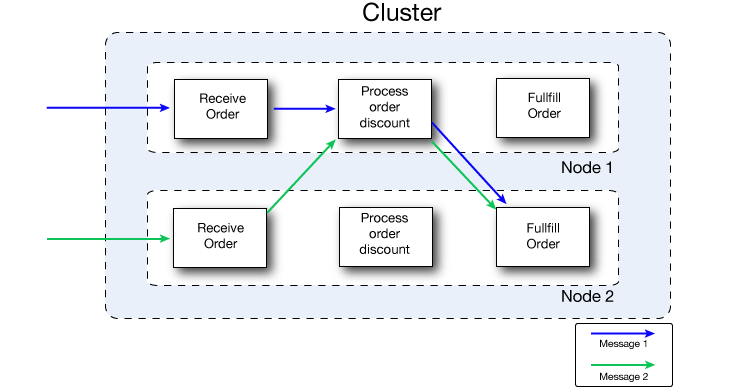
The following figure illustrates workload sharing in more detail. Both nodes process messages related to order fulfillment. However, when one node is heavily loaded, it can move the processing for one or more steps in the process to another node. Here, processing of the Process order discount step is moved to Node 1, and processing of the Fulfill order step is moved to Node 2.
Beyond benefits such as high availability through automatic failover, improved performance, and enhanced scalability, clustering Mule instances offers the following benefits:
-
Automatic coordination of access to resources such as files, databases, and FTP sources. Mule automatically manages which node handles communication from a data source.
-
Automatic load balancing of processing within a cluster. If you divide your flows into a series of steps and connect these steps with a transport such as VM, each step is put in a queue, making it cluster enabled. Mule can then process each step in any node, and so better balance the load across nodes.
-
Cluster lifecycle management and control. See Managing Mule High Availability (HA) Clusters.
-
Cluster and node performance monitoring. See Monitoring a Cluster.
-
Raised alerts. You can set up an alert to appear when a node goes down and when a node comes back up.
| All Mule instances in a cluster actively process messages. Note that Mule is internally scalable – a single Mule instance can scale easily by taking advantage of multiple cores. Even when a Mule instance takes advantage of multiple cores, it still operates as a single server or node in a cluster. |
About Clustering
A Mule ESB Cluster consists of 2 - 8 Mule ESB server instances, or nodes, grouped together and treated as a single unit. Thus, you can deploy, monitor, or stop all the nodes in a cluster as if they were a single Mule server.
All the nodes in a cluster share memory, as illustrated below:
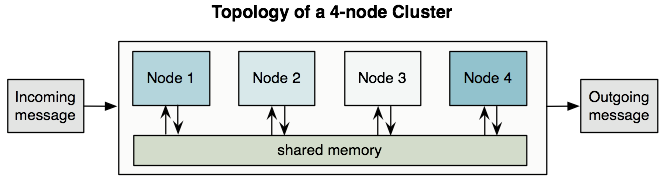
Mule uses an active-active model to cluster servers, rather than an active-passive model.
In an active-passive model, one server in a cluster acts as the primary, or active node, while the others are secondary, or passive nodes. The application in such a model runs on the primary server, and only ever runs on the secondary server if the first one fails. In this model, the processing power of the secondary node(s) is mostly wasted in passive waiting for the primary node to fail.
In an active-active model, no one server in the cluster acts as the primary server; all servers in the cluster support the application. This application in this model runs on all the servers, even splitting apart message processing between nodes to expedite processing across nodes.
About Queues
You can set up a VM queue explicitly to load balance across nodes. Thus, if your entire application flow contains a sequence of child flows, Mule can assign each successive child flow to whichever node happens to be available at the time. Potentially, Mule can process a single message on multiple nodes as it passes through the entire application flow, as illustrated below:
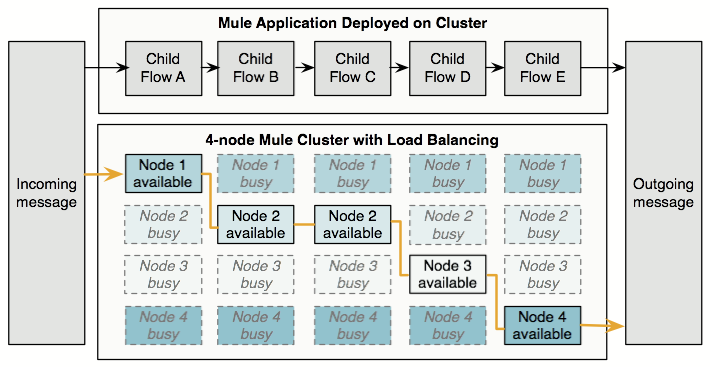
About High-Reliability Applications
A high-reliability application must feature the following:
-
Zero tolerance for message loss
-
Reliable underlying enterprise service bus (ESB)
-
Highly reliable individual connections
The feature known as transactionality tracks application event sequences to ensure that each message-processing step gets completed successfully, and therefore, no messages get lost or processed incorrectly. If a step fails, for some reason, the transactional mechanism rolls back all previous processing events, then restarts the message processing sequence again.
Transports such as JMS, VM, and JDBC provide built-in transactional support, thus ensuring that messages get processed reliably. For example, you can configure a transaction on an inbound JMS endpoint to remove messages from the JMS server only after the transaction has been committed. This ensures that the original message remains available for reprocessing if an error occurs during the processing flow.
You must use XA transactions to move messages between dissimilar transports that support transactions. This ensures that the Mule commits associated transactions from both transports as a single unit. See Transaction Management for more information on XA and other types of transactions supported by Mule.
Cluster Support for Transports
All Mule transports are supported within a cluster. Because of differences in the way different transports access inbound traffic, the details of this support very. In general, outbound traffic acts the same way inside and outside a cluster – the differences are highlighted below.
Mule supports three basic types of transports:
-
Socket-based transports read input sent to network sockets that Mule owns. Examples include TCP, UDP, and HTTP[S].
-
Listener-based transports read data using a protocol that fully supports concurrent multiple accessors. Examples include JMS and VM.
-
Resource-based transports read data from a resource that allows multiple concurrent accessors, but does not natively coordinate their use of the resource. For instance, suppose multiple programs are processing files in the same shared directory by reading, processing, and then deleting the files. These programs must use an explicit, application-level locking strategy to prevent the same file from being processed more than once. Examples of resource-based transports include File, FTP, SFTP, E-mail, and JDBC.
All three basic types of transports are supported in clusters in different ways, as described below.
-
Socket-based
-
Since each clustered Mule instance runs on a different network node, each instance receives only the socket-based traffic sent to its node. Incoming socket-based traffic should use Clustering and Load Balancing to distribute the traffic among the clustered instances.
-
Output to socket-based transports is written to a specific host/port combination. If the host/port combination is an external host, no special considerations apply. If it is a port on the local host, consider using that port on the load balancer instead to better distribute traffic among the cluster.
-
-
Listener-based
-
Listener-based transports fully support multiple readers and writers. No special considerations apply either to input or to output.
-
Note that, in a cluster, VM transport queues are a shared, cluster-wide resource. The cluster automatically synchronizes access to the VM transport queues. Because of this, a message written to a VM queue can be processed by any cluster node. This makes VM ideal for sharing work among cluster nodes.
-
-
Resource-based
-
Mule HA Clustering automatically coordinates access to each resource, ensuring that only one clustered instance accesses each resource at a time. Because of this, it is generally a good idea to immediately write messages read from a resource-based transport to VM queues. This allows the other cluster nodes to take part in processing the messages.
-
There are no special considerations in writing to resource-based clustered transports:
-
When writing to file-based transports (File, FTP, SFTP), Mule will generate unique file names.
-
When writing to JDBC, Mule can generate unique keys.
-
Writing e-mail is effectively listener-based rather than resource-based.
-
-
Clustering and Reliable Applications
High-reliability applications (ones that have zero tolerance for message loss) not only require the underlying ESB to be reliable, but that reliability needs to extend to individual connections. Reliability Patterns give you the tools to build fully reliable applications in your clusters.
Current Mule documentation provides code examples that show how you can implement a reliability pattern for a number of different non-transactional transports, including HTTP, FTP, File, and IMAP. If your application uses a non-transactional transport, follow the reliability pattern. These patterns ensure that a message is accepted and successfully processed or that it generates an "unsuccessful" response allowing the client to retry.
If your application uses transactional transports, such as JMS, VM, and JDBC, use transactions. Mule’s built-in support for transactional transports enables reliable messaging for applications that use these transports.
These actions can also apply to non-clustered applications.
Clustering and Load Balancing
When Mule clusters are used to serve TCP requests (where TCP includes SSL/TLS, UDP, Multicast, HTTP, and HTTPS), some load balancing is needed to distribute the requests among the clustered instances. There are various software load balancers available, two of them are:
-
Nginx, an open-source HTTP server and reverse proxy. You can use Nginx’s HttpUpstreamModule for HTTP(S) load balancing. You can find further information in the Linode Library entry Use Nginx for Proxy Services and Software Load Balancing.
-
The Apache web server, which can also be used as an HTTP(S) load balancer.
There are also many hardware load balancers that can route both TCP and HTTP(S) traffic.
HA Demo
To evaluate Mule’s HA clustering capabilities first-hand, download the Mule HA Demo Bundle. Designed to help new users evaluate the capabilities of Mule High Availability Clusters, the Mule HA Demo Bundle teaches you how to use the Mule Management Console to create a cluster of Mule instances, then deploy an application to run on the cluster. Further, this demo simulates two processing scenarios that illustrate the cluster’s ability to automatically balance normal processing load, and its ability to reliably remain active in a failover situation.
Best Practices
There are a number of recommended practices related to clustering. These include:
-
As much as possible, organize your application into a series of steps where each step moves the message from one transactional store to another.
-
If your application processes messages from a non-transactional transport, use a reliability pattern to move them to a transactional store such as a VM or JMS store.
-
Use transactions to process messages from a transactional transport. This ensures that if an error is encountered, the message will be reprocessed.
-
Use distributed stores such as those used with the VM or JMS transport – these stores are available to an entire cluster. This is preferable to the non-distributed stores used with transports such as File, FTP, and JDBC – these stores are read by a single node at a time.
-
Use the VM transport to get optimal performance. Use the JMS transport for applications where data needs to be saved after the entire cluster exits.
-
Create the number of nodes within a cluster that best meets your needs.
-
Implement reliability patterns to create high reliability applications.
Prerequisites and Limitations
-
Currently you can create a cluster consisting of at least two servers and up to a maximum of eight. However, each server must run in a different physical (or virtual) machine.
-
To maintain synchronization between the nodes in the cluster, Mule HA requires a reliable network connection between servers.
-
You must keep the following ports open in order to set up a Mule cluster: port 5701 and port 54327.
-
Because new cluster member discovery is performed using multicast, you need to enable the multicast IP: 224.2.2.3
-
To serve TCP requests, some load balancing across a Mule cluster is needed. See Clustering and Load Balancing for more information about third-party load balancers that you can use. You can also load balance the processing within a cluster by separating your flows into a series of steps and connecting each step with a transport such as VM. This cluster enables each step, allowing Mule to better balance the load across nodes.
-
Multicasting must be enabled for each server in the cluster. This enables the instances to find each other.
-
If your custom message source does not use a message receiver to define node polling, then you must configure your message source to implement a ClusterizableMessageSource interface.
ClusterizableMessageSource dictates that only one application node inside a cluster contains the active (i.e. started) instance of the message source; this is the ACTIVE node. If the active node falters, the ClusterizableMessageSource selects a new active node, then starts the message source in that node.
See Also
-
Download a trial of Mule with the Mule Management Console to experiment with High Availability. (Download Runtime - Mule ESB Enterprise (with Management Tools).)
-
Install an Enterprise License to begin using the Mule Management Console to manage clusters in production.