Flow Processing Strategies
| Mule Runtime Engine versions 3.5, 3.6, and 3.7 reached End of Life on or before January 25, 2020. For more information, contact your Customer Success Manager to determine how you can migrate to the latest Mule version. |
A flow processing strategy determines how Mule implements message processing for a given flow.
-
Should the message be processed synchronously (on the same thread) or asynchronously (on a different thread)?
-
Should the message be Non-Blocking Processing Strategy? (Available in Mule 3.7 and newer)
-
If asynchronously, what are the properties of the pool of threads used to process the messages?
-
If asynchronously, how do messages wait for their turn to be processed in the second thread?
All Mule flows have an implicit processing strategy which Mule applies automatically: either synchronous or queued-asynchronous. Each of these processing strategies is optimal for certain flows. This page introduces these processing strategies and the criteria Mule uses to determine the optimal processing strategy for each flow.
This page also explains the circumstances under which you may want to override Mule’s choice of processing strategy and covers the parameters you can change or fine-tune in the processing strategy used for a given flow.
Prerequisites
This page assumes that you are familiar with Mule flows and basic application architecture.
Implicit Processing Strategies
Even if you do not configure a processing strategy for your flow, the flow follows a processing strategy automatically applied by Mule. The processing strategy can be:
-
Synchronous Flow Processing Strategy : Mule processes messages in a single thread.
-
Queued-Asynchronous Flow Processing Strategy : Mule uses a queue to decouple the receiver thread from the rest of the flow.
For the majority of use cases, the implicit strategy selected by Mule is optimal. See Changing the Processing Strategy for more information about why and how you can override the implicit processing strategy, if your use case demands it.
How Mule Selects a Flow Processing Strategy
Each flow varies in the degree to which it can benefit from the transactional reliability of synchronous processing, as opposed to the high throughput of the queued-asynchronous alternative.
Mule selects a processing strategy for a flow based on two criteria:
-
The flow’s exchange pattern
-
Whether or not the flow is transactional
A flow employs one of two exchange patterns, determined by the exchange pattern of the flow’s inbound endpoint:
-
A request-response exchange pattern is used when the sender of the messages, such as the flow’s inbound endpoint expects a response or some kind of result to return to the caller.
-
A one-way exchange pattern is used when no response is expected, or when the result is sent to some other flow or system and not back to the caller.
If the exchange pattern is request-response, Mule applies a synchronous processing strategy.
In addition, some inbound endpoints can be configured to operate transactionally, regardless of their exchange pattern. If a flow is transactional, Mule applies a synchronous processing strategy.
The following table summarizes how Mule chooses a flow processing strategy:
| Exchange Pattern | Transactional? | Flow Processing Strategy |
|---|---|---|
Request-Response |
Yes |
Synchronous |
Request-Response |
No |
Synchronous |
One-way |
Yes |
Synchronous |
One-way |
No |
Queued-Asynchronous |
Changing the Processing Strategy
Mule’s choice of processing strategy is almost always optimal for the flow to which it is applied. However, the following options exist:
-
Change to Synchronous - In cases where Mule has selected queued-asynchronous processing for a flow, you can specify a synchronous flow instead. You might want to specify a synchronous flow to achieve reliability. Remember that the synchronous strategy is ideally suited for flows where the flow’s inbound endpoint must be notified of all errors that occur during the processing of the message. The Reliability Patterns document discusses this situation further. Although this is not applicable to most use cases, if Mule has selected queued-asynchronous processing for a flow, you can specify another kind of asynchronous processing strategy instead. Note: You cannot force a queued-asynchronous processing strategy on a synchronous flow.
-
Fine Tune: You can accept Mule’s choice of the queued-asynchronous flow processing strategy, but then fine-tune the processing strategy. Note: You cannot fine-tune a synchronous flow.
-
Wrap a Flow: You can wrap one or more message processors within your synchronous flow in an asynchronous scope to define a processing block that Mule processes asynchronously with the main flow. You can also create an asynchronous flow by wrapping a flow-ref in an asynchronous scope.
-
Subflow: You can call out to a subflow (which always processes synchronously) or a synchronous flow from any flow, regardless of what processing strategy is applied to the triggering flow. The triggering flow waits until this synchronous processing block returns a message before proceeding with processing. See Flows and Subflows for more information about subflows and synchronous flows.
-
Non-Blocking: You can use the new Non-Blocking Processing Strategy strategy available in Mule 3.7 and newer to take advantage of NIO with the HTTP Connector and avoid having threads blocked while waiting for HTTP responses, which also requires less tuning. Note: Not all components are currently supported, unsupported components cause a flow to fall back to synchronous processing.
-
Custom: You can create a custom flow processing strategy to fit your exact needs. For instance, you might prefer a queued-asynchronous flow that uses an increased number of threads to handle high peak loads.
| Additional Processing Strategy Element and Global Element Names | Description |
|---|---|
Non-blocking |
Applicable when using a HTTP Listener at the start of your flow and you use one for more HTTP Requester’s in your flow and your flow does not include any components currently not supported with this strategy. |
Thread-per-processor processing strategy |
Not applicable to most use cases. Every processor in the scope runs sequentially in a different thread. |
Queued thread-per-processor processing strategy |
Not applicable to most use cases. Writes messages to a queue, then every processor in the scope runs sequentially in a different thread. |
Asynchronous processing strategy |
Not applicable to most use cases. Same as queued-asynchronous processing strategy except that it doesn’t use a queue. Use this only if you do not want your processing to be distributed across nodes. |
Summary
| Flow Processing Strategy implictly applied by Mule |
Can you specify a different processing strategy? |
Can you fine-tune the processing strategy? |
Can you create a processing block that executes using a different processing strategy from the main flow? | Can you apply a custom processing strategy using Spring? |
|---|---|---|---|---|
Synchronous |
No. You cannot force a flow with a request-response exchange pattern and/or transactionality to be asynchronous. |
No. You cannot fine-tune the synchronous processing strategy. You can, however, customize the inbound endpoint connector receiver threading profile. |
Yes. You can use an Async Scope or an asynchronous flow to cause Mule to process a selected block of message processors asynchronously. Creating an Asynchronous Processing Block. |
|
Queued-Asynchronous |
Yes. You can override an implicitly selected queued-asynchronous processing strategy by explicitly declaring a synchronous processing strategy (or, in rare use cases, a different kind of asynchronous processing strategy) instead. Specifying a Processing Strategy. |
Yes. You can fine-tune the queued-asynchronous processing strategy to meet your needs. Fine-Tuning a Queued-Asynchronous Processing Strategy. |
Yes. A synchronous flow or subflow processes a selected block of message processors synchronously, regardless of the processing strategy of the main flow. |
Specifying a Processing Strategy
The procedure to change a processing strategy for an individual flow is straightforward. You may only specify a processing strategy for flows to which Mule would implicitly apply a queued-asynchronous processing strategy. Thus, only flows with one-way exchange patterns and which are not transactional can have a processing strategy specified to override Mule’s selection of the queued-asynchronous processing strategy.
The most frequent use case for specifying a processing strategy is to force a flow that would otherwise be queued-asynchronous to be synchronous instead. To force a flow to be synchronous, add the processingStrategy attribute to the flow that you want to change and set it to synchronous. This is illustrated in the code example below.
<flow name="asynchronousToSynchronous" processingStrategy="synchronous">
<vm:inbound-endpoint path="anyUniqueEndpointName" exchange-pattern="one-way"/>
<vm:outbound-endpoint path="output" exchange-pattern="one-way"/>
</flow>In rare use cases, you might want to specify another kind of asynchronous processing strategy on a flow that would otherwise follow a queued-asynchronous processing strategy. You can either declare it directly in the flow configuration, just as in the example immediately above which declares a synchronous processing strategy, or you can create a global element and further fine tune the processing strategy. The table below lists the processing strategy names, which can each be declared as values for the processingStrategy attribute, or as a global element.
| Additional Asynchronous Processing Strategy Element/Global Element Names | Description |
|---|---|
asynchronous-processing-strategy |
Not applicable to most use cases. Same as queued-asynchronous processing strategy except that it doesn’t use a queue. Use this only if for some reason you do not want your processing to be distributed across nodes. |
queued-thread-per-processor-processing-strategy |
Not applicable to most use cases. Writes messages to a queue, then every processor in the scope runs sequentially in a different thread. |
thread-per-processor-processing-strategy |
Not applicable to most use cases. Every processor in the scope runs sequentially in a different thread. |
Fine-Tuning a Queued-Asynchronous Processing Strategy
If Mule has applied a queued-asynchronous flow processing strategy, you can fine-tune it to adjust how it behaves. Note that you can only fine-tune a queued-asynchronous strategy; you cannot do any fine-tuning for a synchronous flow.
You can fine-tune a queued-asynchronous processing strategy by:
-
Changing the number of threads available to the flow.
-
Limiting the number of messages that can be queued.
-
Specifying a queue store to persist data.
You achieve this fine-tuning by specifying parameters for a global processing strategy, then referencing the parameters within the flow or flows you wish to fine-tune. If you don’t specify a certain configuration parameter at either the global or local levels, Mule sets a default value for the parameter. The table below lists these default values.
| Note that in addition to fine-tuning the attributes of the queued-asynchronous processing strategy, you can also tune performance of your Mule application by analyzing and configuring thread profiles. |
The following example defines a global processing strategy (queued-asynchronous-processing-strategy), which sets the maximum number of threads (maxThreads) to 500. The example also shows how a flow references the global processing strategy. This flow:
-
Is asynchronous, because it refers to the queued-asynchronous processing strategy
-
Allows up to 500 concurrent threads, because of the value set for
maxThreads
<queued-asynchronous-processing-strategy name="allow500Threads" maxThreads="500"/>
<flow name="manyThreads" processingStrategy="allow500Threads">
<vm:inbound-endpoint path="manyThreads" exchange-pattern="one-way"/>
<vm:outbound-endpoint path="output" exchange-pattern="one-way"/>
</flow>The following table lists the configuration parameters you can fine-tune for asynchronous processing strategies. (The synchronous processing strategy cannot be configured.) All of these attributes can be configured on the global element.
| Attribute | Type | Queued only? | Default value | Description | Optional? |
|---|---|---|---|---|---|
maxBufferSize |
integer |
no |
1 |
Determines how many requests are queued when the pool reaches maximum capacity and the pool exhausted action is WAIT. The buffer is used as an overflow. |
yes |
maxQueueSize |
integer |
yes |
n/a |
The maximum number of messages that can be queued. |
yes |
maxThreads |
integer |
no |
16 |
The maximum number of threads that can be used. |
yes |
minThreads |
integer |
no |
n/a |
The number of idle threads kept in the pool when there is no load. |
yes |
poolExhaustedAction |
enum |
no |
WHEN_EXHAUSTED_RUN |
When the maximum pool size or queue size is bounded, this value determines how to handle incoming tasks. |
yes |
queueTimeout |
integer |
yes |
n/a |
The timeout used when taking events from the queue. |
yes |
threadTTL |
integer |
no |
60000 |
Determines how long an inactive thread is kept in the pool before being discarded. |
yes |
threadWaitTimeout |
integer |
no |
30000 |
How long to wait in milliseconds when the pool exhausted action is WAIT. If the value is negative, the wait is infinite. |
yes |
doThreading |
boolean |
no |
True |
Whether threading should be used. |
yes |
In addition, you can define a queue store using one of the following nested elements:
| Queue Store nested element | Description |
|---|---|
simple-in-memory-queue-store |
A simple in-memory queue store. |
default-in-memory-queue-store |
This is the default queue store used for non-persistent queues. |
default-persistent-queue-store |
This is the default queue store used for persistent queues. |
file-queue-store |
A simple file queue store. |
queue-store |
A reference to a queue store defined elsewhere. |
custom-queue-store |
A custom queue store defined with Spring properties. |
Creating an Asynchronous Processing Block
If Mule has applied a synchronous processing strategy to your flow, you can separate out a processing block that executes simultaneously with the main flow and does not return messages back to the main flow. Achieve this in one of two ways:
-
Wrap one or more processors in an async scope
-
Create an asynchronous flow by wrapping a flow-ref element in an async scope so that the contents of the flow will be processed asynchronously with the triggering flow
Both of these methods allow you to block off a set of processing steps that may be very time consuming to execute. Because this asynchronous processing block is one-way, the main flow does not wait for a response and is free to continue processing in the main thread.
If no processing strategy is configured for the async scope, Mule applies a queued-asynchronous processing strategy. However, you can specify or fine-tune the asynchronous processing strategy of the scope by defining a global element and referencing it from the async element.
The following global elements are available for configuring the processing strategy of an asynchronous scope.
| Global Element | Description |
|---|---|
asynchronous-processing-strategy |
Not applicable to most use cases. Same as queued-asynchronous processing strategy (which is what Mule applies if no other processing strategy is configured) except that it doesn’t use a queue. Use this only if for some reason you do not want your processing to be distributed across nodes. |
queued-asynchronous-processing-strategy |
Uses a queue to decouple the flow’s receiver from the rest of the steps in the flow. It works the same way in a scope as in a flow. Mule applies this strategy unless another is specified. Select this if you want to fine-tune this processing strategy by:
|
queued-thread-per-processor-processing-strategy |
Not applicable to most use cases. Writes messages to a queue, then every processor in the scope runs sequentially in a different thread. |
thread-per-processor-processing-strategy |
Not applicable to most use cases. Every processor in the scope runs sequentially in a different thread. |
For more information about configuring the asynchronous scope element, refer to the Async Scope reference.
Creating a Custom Processing Strategy
If neither the synchronous nor queued-asynchronous processing strategies fit your needs, and fine-tuning the asynchronous strategy is not sufficient, you can create a custom processing strategy. You create the custom strategy through the custom-processing-strategy element and configure it using Spring bean properties. This custom processing strategy must implement the org.mule.api.processor.ProcessingStrategy interface.
The following code example illustrates a custom processing strategy:
<custom-processing-strategy name="customStrategy" class="org.mule.CustomProcessingStrategy">
<spring:property name="threads" value="500"/>
</custom-processing-strategy>Reusing Processing Strategies
You can use a named processing strategy, either a custom processing strategy that you have created or a fine-tuned processing strategy, on as many flows in an application as you like.
-
Declare the processing strategy, as in the following:
<queued-asynchronous-processing-strategy name="allow500Threads" maxThreads="500"/> -
Refer to it in appropriate flows, for instance:
<flow name="acceptOrders" processingStrategy="allow500Threads"> <vm:inbound-endpoint path="acceptOrders" exchange-pattern="one-way"/> <vm:outbound-endpoint path="commonProcessing" exchange-pattern="one-way"/> </flow> <flow name="processNewEmployee" processingStrategy="allow500Threads"> <vm:inbound-endpoint path="processNewEmployee" exchange-pattern="one-way"/> <vm:outbound-endpoint path="commonProcessing" exchange-pattern="one-way"/> </flow> <flow name="receiveInvoice" processingStrategy="allow500Threads"> <vm:inbound-endpoint path="receiveInvoice" exchange-pattern="one-way"/> <vm:outbound-endpoint path="commonProcessing" exchange-pattern="one-way"/> </flow>
Synchronous Flow Processing Strategy
The synchronous approach is used to process messages in the same thread that initially received the message. After the flow receives a message, all processing, including the processing of the response, is done in that same thread (with the exception of asynchronous scopes like Async and For Each.) The synchronous strategy is ideally suited to flows where:
-
The sender of the message expects a response. This is known as a "request-response" exchange pattern.
-
The flow needs to meet the requirements of transactional processing. In other words, all the steps in the flow are considered a single unit, which must succeed entirely or fail entirely. Additionally, appropriate parties (such as the sender of the message or the administrator of the business process encapsulated by the flow) must be notified of the result. This means that a transactional flow must not hand off processing to other threads, where errors can occur after the transaction is completed.
-
The flow’s inbound endpoint must be notified of all errors that occur during the processing of the message. This situation is discussed further in Reliability Patterns.
Queued-Asynchronous Flow Processing Strategy
The queued-asynchronous approach uses a queue to decouple the flow’s receiver from the rest of the steps in the flow.
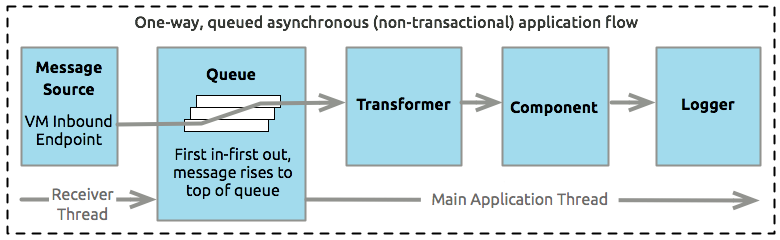
This means that once the receiver places a message into a queue, it can immediately return and accept a new incoming message. Furthermore, each message waiting in the queue can be assigned a different thread from a pool of threads. A component called a Work Manager assigns pending messages to available threads, so they can be processed in parallel. Such parallel processing is ideal for situations where the receiver can, at peak times, accept messages significantly faster than the rest of the flow can process those messages.
However, the increased throughput facilitated by the asynchronous approach comes at the cost of transactional reliability.
| The specific type of queue implemented for the queued-asynchronous flow processing strategy is known as a SEDA queue. |
|
Behavior in a Cluster A flow with an queued-asynchronous processing strategy can execute on any node in a cluster. A flow with a synchronous processing strategy executes on the same node of the cluster until processing in the flow is complete. |
Non-Blocking Processing Strategy
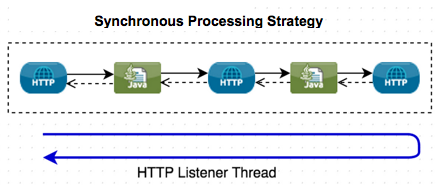
Mule has traditionally always used a threaded processing model for handling incoming requests from a Message Sources using the request-response Message Exchange Pattern. This means that the whole Mule Flow, both request and response phases, are executed using the same thread. This same thread is also used to send the response back to the client. This threaded request-response processing is used whenever the Fine-Tuning a Queued-Asynchronous Processing Strategy is used, either explicitly or by Mule implicitly selecting this strategy when one isn’t specified. This processing model can more easily be shown with this diagram:
The non-blocking processing strategy in contrast uses an evented non-blocking processing model to process requests. In this model a single thread still handles each incoming request, but non-blocking components return this thread to the listener thread pool. Only upon obtaining and using a new thread, can processing continue.This is much easier to explain with the example below that uses HTTP, which can also be directly compared to the threaded example above.
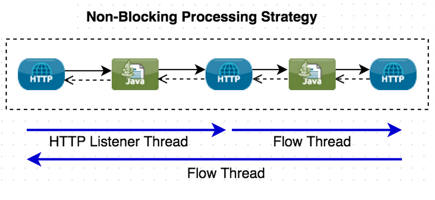
In this example, the HTTP components support Non-Blocking I/O (NIO).
This means that:
-
The HTTP Request processor internally doesn’t need a thread to wait for a response, but rather receives an event when the response is available.
-
The HTTP Listener message source can send the client response using any thread when the response is ready. While these components support this model, it is only using the non-blocking processing strategy that Mule can take advantage of this.
The thread usage can be explained as followed.
-
The request is handled by a listener thread as with the synchronous processing strategy.
-
Given the HTTP Request processor supports non-blocking, it frees up the listener thread once the request is sent.
-
No threads are in use between sending the HTTP request and receiving the HTTP response.
-
Once a response is available, the HTTP Request process obtains a new thread to continue processing from the Flow thread pool.
-
Processing then continues using the flow thread and the same happens whenever a non-blocking processor is encountered
-
Finally, the HTTP Listener response is sent back using whichever thread is currently processing the flow, in this case it is a flow thread.
Note: The non-blocking flow thread pool has a default maximum of 128 threads, which differs from the default maximum number of threads in the other processing strategies. The 128 value matches the default number of threads used by the HTTP listener, so in the scenario above, a maximum of 128 threads are available for both processing requests and sending responses.
It is important to understand that both processing strategies functionally achieve the same result. The difference is that Mule threads are in use for longer with the synchronous processing strategy as they are blocked while waiting for responses from the HTTP Request processors, while with the non-blocking strategy threads are available when needed.
Non-Blocking Advantages
The main advantage of this processing-strategy is that in a flow that uses this processing strategy, as long as the flow doesn’t block for I/O or use Thread.sleep() anywhere, no tuning is required to achieve optimum performance. With the synchronous processing strategy, by comparison, it is necessary to tune the listener thread pool size based on the expected usage of the flow.
Let’s consider an example using the example flow above:
-
Current number of concurrent clients: 1000
-
Current response time from HTTP request calls: 250 ms each
-
Target threads per second (TPS): 1000
If our example flow has two outbound HTTP request calls, the total time the listener thread is in use processing an incoming request is 0.5 seconds. This means that with the default listener thread pool size of 128, the maximum TPS that can be achieved is 256 TPS. This is calculated as follows:
-
TPS = min(client threads, listener threads) / outbound HTTP response time * 2.
-
TPS = 128/0.5
-
TPS = 256
To achieve a target of 1000 TPS, you would need to configure 500 listener threads. It’s not ideal that this tuning is required out of the box, but what is worse is that this tuning is often short-lived, because if the client concurrency increases, not only does the TPS not increase, but the response time increases relative to the increase in concurrency. On the other hand, if the processing time increases to 1s, then the maximum TPS of the tuned flow is 500 TPS regardless of how many clients there are.
One solution to this is to always tune using a very high number of threads to plan for all eventualities, but this isn’t a good idea because threads consume resources, there is a direct memory buffer per thread, and depending on the operating systems in use, there can be overhead associated with using a large number of threads concurrently.
For reference the TPS calculation with non-blocking would be:
TPS = client threads / outbound HTTP response time * 2
Note that the performance of the flow with non-blocking is not dependent on any tuning of the flow or Mule application, but is rather only dependent on external factors such as client threads and response time. As well as, of course, any CPU or network sets the bounds.
When to Use Non-Blocking
While this processing model clearly applies to multiple scenarios in Mule’s current support, it limits and focuses specifically on request-response flows using HTTP, which is where this processing strategy is most valuable.
Therefore, you should consider using this processing strategy when your flow implementations primarily use HTTP and you want the advantage of not needing to tune listener threads or to minimize resource utilization, as described above,
Before using the non-blocking strategy, ensure you are also familiar with what is currently supported and their limitations as follows:
-
The only Message Source that supports non-blocking is the HTTP Connector Listener.
-
The only Message Processor that supports non-blocking is the HTTP Connector Request.
-
The only Message Exchange Pattern currently supported is Request-Response.
-
Only a limited set of components are fully supported for use in non-blocking flows.
While you can use unsupported components in a non-blocking flow, they cause the processing model to revert to execute synchronously so as to ensure consistent behavior. Aside from advanced scenarios, in these cases, it is best to not to use the non-blocking processing strategy.
Supported Non-Blocking Components
-
Connectors: All connectors are supported in a non-blocking flow, but only the HTTP connector (introduced in Mule 3.6 and newer) performs non-blocking request-response operations and lets you take advantage of the non-blocking processing model.
-
Scopes:
-
Processor-Chain, Subflow and Enricher: Are fully supported and HTTP Connector Request components inside these scopes take advantage of the non-blocking processing model.
-
Async/Wire-Tap: Supported, but child processors cannot take advantage of non-blocking processing. This is because the One-Way Exchange-Pattern is not yet supported.
-
Request-Reply: Supported, but does not currently take advantage of the non-blocking processing model.
-
-
Components: All components are supported.
-
Transformers: All transformers including DataWeave.
-
Filters: All filters are supported.
-
Flow Control: Currently only the APIkit Router and Choice are supported.
-
Error Handling: All exception strategies are supported, but currently HTTP Connector request elements cannot execute non-blocking when inside an exception strategy.
Unsupported Components
-
Scopes:
-
Transactional: This scope requires processing to be single-threaded and is therefore implicitly unsupported
-
Until-Successful
-
-
Flow Control: No Flow Control elements other than APIkit Router and Choice are currently supported.
Synchronous Fallback
If an unsupported component is configured in a flow that is using the non-blocking processing strategy, then the flow reverts to the synchronous processing from the point in the flow. There may be advanced cases where this is desirable to take advantage of non-blocking for part of the flow, but typically it is best to stick with the synchronous processing strategy.
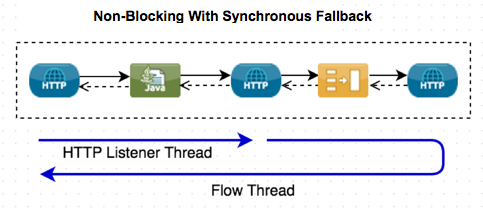
In this example the first HTTP request processor uses non-blocking, but the aggregator after it forces the flow to revert to synchronous behavior and as such the second HTTP request processor does not use non-blocking and the flow thread waits for a response before sending the response back to the client.
See Also
-
Refer to the Async Scope Reference for information on how to embed an asynchronous processing block in an otherwise synchronous flow.
-
Review the different kinds of Flows and Subflows in Mule.
-
Read more about Reliability Patterns.
-
Find out how to tune performance by analyzing and configuring threading profiles.
-
Check out the Asynchronous Message Cheat Sheet on our MuleSoft Blog.