Batch Filters and Batch Commit
| Mule runtime engine version 3.8 reached its End of Life on November 16, 2021. For more information, contact your Customer Success Manager to determine how to migrate to the latest Mule version. |
Enterprise, CloudHub
Using batch processing, you can refine the work that a batch step performs upon the records it processes.
-
You can set filters upon batch steps so as to only accept some records for processing.
-
You can commit records in groups, sending them as bulk upserts to external sources or services.
This document outlines how and when to use batch filters and the batch commit wrapper.
Prerequisites
This document assumes that you are familiar with Anypoint Studio, have reviewed the overview and basic anatomy of Batch Processing, and that you understand how batch jobs handle records which fail processing. You should also consider Streaming Batch Commits.
Filters
You can apply one or more filters as attributes to any number of batch steps within your batch job. By having batch steps accept only some records for processing, you streamline processing so that Mule focuses only on the data which is relevant for a particular batch step.
For example, you could apply a filter to the second batch step in your batch job to make sure that the second step only attempts to process records which didn’t fail during processing in the first batch step. To put this in context of a use case, imagine a batch job which uses its first batch step to check to see if a Salesforce contact exists for a record; the second batch step updates each existing Salesforce contact with new information. In such a case, you could apply a filter to the second batch step to ensure it only processes records that didn’t fail during the first batch step.
Filters are applied within batch steps. Use an Accept Expression to process only those records which, relative to the MEL expression, evaluate to true; if the record evaluates to false, the batch step does not process the record. In other words, those records with a filter expression that resolves to false are the ones Mule filters out.
The example below filters out all records where the age is less than 21; the batch step does not process those records.
Studio Visual Editor
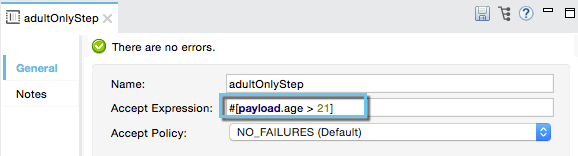
XML Editor
Note that details in code snippet are abbreviated so as to highlight batch step attributes.
<batch:step name="adultsOnlyStep" accept-expression="#[payload.age > 21]">Use an Accept Policy to process only those records which, relative to the value of the accept policy attribute, evaluate to true. Refer to the table below for a list of the available values for the accept policy. The example below illustrates the second batch step in a batch job that processes only those records that failed processing during the preceding step. In the first batch step, Mule checked each record to see if it had an existing Salesforce contact; the second batch step, which creates a contact for each record, processes only the failed records (that is, records that failed to have an existing account).
| Accept Policy | When evaluates to TRUE |
|---|---|
NO_FAILURES |
Default |
ONLY_FAILURES |
Batch step processes only those records that failed processing in a preceding batch step |
ALL |
Batch step processes all records, regardless of whether they failed processing in a preceding batch step |
Studio Visual Editor
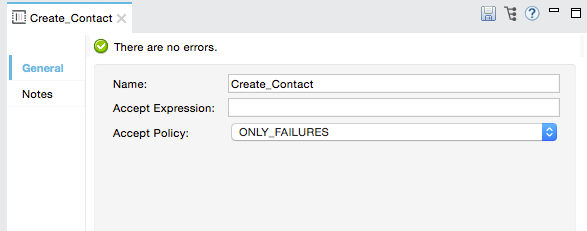
XML Editor
Note that details in the code snippet are abbreviated so as to highlight batch step attributes.
<batch:step name="Create_Contact" accept-policy="ONLY_FAILURES" doc:name="Create Contact">Filter Characteristics
-
Batch filters only apply to batch steps which, in turn, are only usable within the batch process phase of a batch job. You cannot apply filters with the Input or On Complete phases.
-
If you don’t apply filters to a batch step, the batch processes only those records that succeeded processing in all preceding steps. In other words, the default Accept Policy applied to all batch steps is NO_FAILURES.
-
When a batch job instance exceeds its
max-failed-recordsvalue, regardless of the filter set on the batch step, the step does not process any records, and simply pushes the failed batch job instance to the On Complete phase. Read more about failure handling in batch jobs. -
Refer to Batch Reference for details regarding batch step attributes.
-
Where you apply both types of filters, Mule evaluates them in the following order:
-
Accept Policy
-
Accept Expression
-
Batch Commit
You can use a Batch Commit scope in a batch step to accumulate a subset of records within a batch for bulk upsert to an external source or service. For example, rather than upserting each individual contact (that is, a record) in a batch to Google Contacts, you can configure a Batch Commit to accumulate, say, 100 records, then upsert all of them to Google Contacts in one chunk.
Within a batch step, the only place you can apply it, you use a Batch Commit to wrap an outbound message source. See the example below.
Note: See also Streaming Batch Commits.
Studio Visual Editor
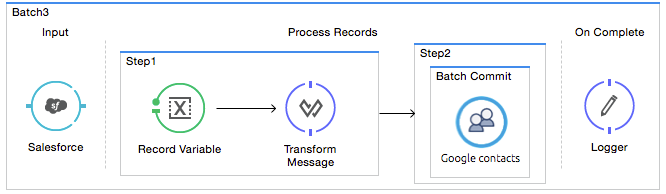
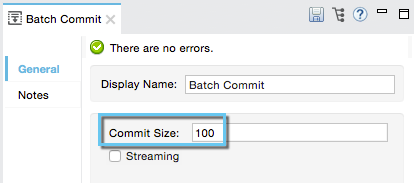
XML Editor
Note that details in code snippet are abbreviated so as to highlight batch commit and its attributes.
<batch:step name="Step2">
<batch:commit size="100">
<google-contacts:/>
</batch:commit>
</batch:step>Batch Commit Characteristics
-
Batch Commit scopes can only exist in batch steps which, in turn, are only usable within the batch process phase of a batch job. You cannot use batch commits within the Input or On Complete phases.
-
A commit can only wrap the final element within the batch step in which it resides.
-
Several Anypoint Connectors have the ability to handle record-level errors without failing a whole batch commit (i.e. upsert). At runtime, these connectors keep track of which records were successfully accepted by the target resource, and which failed to upsert. Thus, rather than failing a complete group of records during a commit activity, the connector simply upserts as many records as it can, and tracks any failures for notification. The short – but soon to grow – list of such connectors follows:
-
Salesforce
-
Google Contacts
-
Google Calendars
-
NetSuite
-
-
Refer to Batch Reference for details regarding batch step attributes.
-
Batch processing does not support job-instance-wide transactions. You can define a transaction inside a batch step that processes each record in a separate transaction. (Think of it like a step within a step.) Such a transaction must start and end within the step’s boundaries.
-
You cannot share a transaction between a batch step and a batch commit that exists within the step. Any transaction that the batch step starts, ends before the batch commit begins processes. In other words, a transaction cannot cross the barrier between a batch step and the batch commit it contains.
Mutable Records Inside Commit Blocks
In previous versions of Mule, the commit block exposed only the grouped record’s payload and didn’t allow you to change those payloads nor to retrieve the associated record variables. Since 3.8, Mule allows you to access the grouped records' payloads and variables from within the Batch commit block and process them using the Mule Expression Language (MEL).
Sequential Access
You can persistently go over each record’s payload and sequentially store it as a record variable.
During the process phase of your batch job, you can replace, change, or store the payload data.
By adding a Foreach Scope you can iterate trough a fixed size commit block, and use the Expression Component Reference to modify the payload and create a record variable for each collected record.
<batch:step name="commitStep">
<batch:commit size="10">
<foreach>
<expression-component>
record.payload = 'foo';
record.recordVars['marco'] = 'polo';
</expression-component>
</foreach>
</batch:commit>
</batch:step>The sequential access method assumes that:
-
The commit size matches the amount of aggregated records.
-
There is a direct correlation between the aggregated records and the items in the list.
Random Access
You can use the records variable to access random records without the need of iterating. This variable provides a random access list that is accessible across the commit block.
The counter variable is an immutable list used by Foreach to keep track of the iteration.
|
You can carry out the same result as the example above by specifying an arbitrary index number for the records list instead of sequentially access each record:
<batch:step name="commitStep">
<batch:commit size="10">
<foreach>
<expression-component>
records[0].payload = 'foo';
records[0].recordVars['marco'] = 'polo';
</expression-component>
</foreach>
</batch:commit>
</batch:step>Using random access, you can change a record’s payload at any index position in the commit block.
|
Due to memory restrictions, random access is not supported for streaming commits. The record payloads for random access are exposed as an When streaming commits, always use the sequential access method. |
Examples
This example uses batch processing to address a use case in which the contents of a comma-separated value file (CSV) of leads – comprised of names, birthdays, and email addresses must be uploaded to Salesforce. To avoid duplicating any leads, the batch job checks to see if a lead exists before uploading data to Salesforce.
For more information, see:
-
Batch Processing for a full description of the steps the batch job takes in each phase of processing.
The insert-lead batch step employs both an Accept Expression and Batch Commit (see below).
XML Editor
|
If you copy and paste the code into your instance of Studio, be sure to enter your own values for the global Salesforce connector:
How do I get a Salesforce security token?
|
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns="http://www.mulesoft.org/schema/mule/core" xmlns:batch="http://www.mulesoft.org/schema/mule/batch" xmlns:context="http://www.springframework.org/schema/context" xmlns:doc="http://www.mulesoft.org/schema/mule/documentation" xmlns:dw="http://www.mulesoft.org/schema/mule/ee/dw" xmlns:file="http://www.mulesoft.org/schema/mule/file" xmlns:metadata="http://www.mulesoft.org/schema/mule/metadata" xmlns:sfdc="http://www.mulesoft.org/schema/mule/sfdc" xmlns:spring="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-current.xsd
http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/file http://www.mulesoft.org/schema/mule/file/current/mule-file.xsd
http://www.mulesoft.org/schema/mule/batch http://www.mulesoft.org/schema/mule/batch/current/mule-batch.xsd
http://www.mulesoft.org/schema/mule/sfdc http://www.mulesoft.org/schema/mule/sfdc/current/mule-sfdc.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-current.xsd
http://www.mulesoft.org/schema/mule/ee/dw http://www.mulesoft.org/schema/mule/ee/dw/current/dw.xsd">
<sfdc:config doc:name="Salesforce" name="Salesforce" username="username" password="password" securityToken="devToken">
<sfdc:connection-pooling-profile exhaustedAction="WHEN_EXHAUSTED_GROW" initialisationPolicy="INITIALISE_ONE"/>
</sfdc:config>
<batch:job max-failed-records="1000" name="CreateLeadsBatch">
<batch:threading-profile poolExhaustedAction="WAIT"/>
<batch:input>
<file:inbound-endpoint doc:name="Poll CSV files" moveToDirectory="src/main/resources/output" path="src/main/resources/input" pollingFrequency="10000" responseTimeout="10000"/>
<dw:transform-message doc:name="Transform CSV to Maps" metadata:id="7bff9652-407a-4479-9e4a-6f82f57ec3f6">
<dw:set-payload><![CDATA[%dw 1.0
%output application/java
---
payload map {
Company : $.Company,
Email : $.Email,
FirstName : $.FirstName,
LastName : $.LastName
}]]></dw:set-payload>
</dw:transform-message>
</batch:input>
<batch:process-records>
<batch:step name="LeadExistsStep">
<enricher doc:name="Message Enricher" source="#[payload.size() > 0]" target="#[recordVars['exists']]">
<sfdc:query config-ref="Salesforce" doc:name="Find Lead" query="dsql:SELECT Id FROM Lead WHERE Email = '#[payload["Email"]]'"/>
</enricher>
</batch:step>
<batch:step accept-expression="#[!recordVars['exists']]" name="LeadInsertStep">
<logger doc:name="Log the lead" level="INFO" message="Got Record #[payload], it exists #[recordVars['exists']]"/>
<batch:commit doc:name="Batch Commit" size="200">
<sfdc:create config-ref="Salesforce" type="Lead" doc:name="Insert Lead">
<sfdc:objects ref="#[payload]"/>
</sfdc:create>
</batch:commit>
</batch:step>
<batch:step accept-policy="ONLY_FAILURES" name="LogFailuresStep">
<logger doc:name="Log Failure" level="INFO" message="Got Failure #[payload]"/>
</batch:step>
</batch:process-records>
<batch:on-complete>
<logger doc:name="Log Results" level="INFO" message="#[payload.loadedRecords] Loaded Records #[payload.failedRecords] Failed Records"/>
</batch:on-complete>
</batch:job>
</mule>Following the example above, assume that you would like to log the generated Salesforce ID of each commit.
You can use the Sequential Access method with a Foreach scope containing the expression: + record.recordVars['sfdcld'] = payload.wrapped.id'. This automatically gets you a variable called `record to hold a reference to one of the aggregated records.
Studio Visual Editor
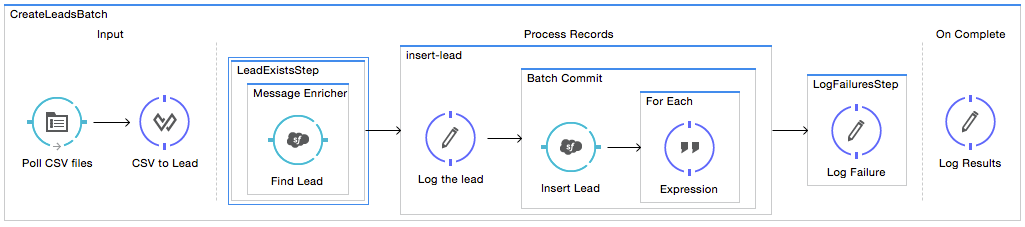
XML Editor
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns="http://www.mulesoft.org/schema/mule/core" xmlns:batch="http://www.mulesoft.org/schema/mule/batch" xmlns:context="http://www.springframework.org/schema/context" xmlns:doc="http://www.mulesoft.org/schema/mule/documentation" xmlns:dw="http://www.mulesoft.org/schema/mule/ee/dw" xmlns:file="http://www.mulesoft.org/schema/mule/file" xmlns:metadata="http://www.mulesoft.org/schema/mule/metadata" xmlns:sfdc="http://www.mulesoft.org/schema/mule/sfdc" xmlns:spring="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-current.xsd
http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/file http://www.mulesoft.org/schema/mule/file/current/mule-file.xsd
http://www.mulesoft.org/schema/mule/batch http://www.mulesoft.org/schema/mule/batch/current/mule-batch.xsd
http://www.mulesoft.org/schema/mule/sfdc http://www.mulesoft.org/schema/mule/sfdc/current/mule-sfdc.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-current.xsd
http://www.mulesoft.org/schema/mule/ee/dw http://www.mulesoft.org/schema/mule/ee/dw/current/dw.xsd">
<sfdc:config doc:name="Salesforce" name="Salesforce" password="${sfdcPassword}" securityToken="${sfdcTOken}" username="${sfdcUser}">
<sfdc:connection-pooling-profile exhaustedAction="WHEN_EXHAUSTED_GROW" initialisationPolicy="INITIALISE_ONE"/>
</sfdc:config>
<batch:job max-failed-records="1000" name="CreateLeadsBatch">
<batch:threading-profile poolExhaustedAction="WAIT"/>
<batch:input>
<file:inbound-endpoint doc:name="Poll CSV files" moveToDirectory="src/main/resources/output" path="src/main/resources/input" pollingFrequency="10000" responseTimeout="10000"/>
<dw:transform-message doc:name="Transform CSV to Maps" metadata:id="7bff9652-407a-4479-9e4a-6f82f57ec3f6">
<dw:set-payload><![CDATA[%dw 1.0
%output application/java
---
payload map {
Company : $.Company,
Email : $.Email,
FirstName : $.FirstName,
LastName : $.LastName
}]]></dw:set-payload>
</dw:transform-message>
</batch:input>
<batch:process-records>
<batch:step name="LeadExistsStep">
<enricher doc:name="Message Enricher" source="#[payload.size() > 0]" target="#[recordVars['exists']]">
<sfdc:query config-ref="Salesforce" doc:name="Find Lead" query="dsql:SELECT Id FROM Lead WHERE Email = '#[payload["Email"]]'"/>
</enricher>
</batch:step>
<batch:step accept-expression="#[!recordVars['exists']]" name="LeadInsertStep">
<logger doc:name="Log the lead" level="INFO" message="Got Record #[payload], it exists #[recordVars['exists']]"/>
<batch:commit doc:name="Batch Commit" size="200">
<sfdc:create config-ref="Salesforce" type="Lead" doc:name="Insert Lead">
<sfdc:objects ref="#[payload]"/>
</sfdc:create>
<foreach doc:name="For Each">
<expression-component doc:name="Expression"><![CDATA[record.recordVars['sfdcld'] = payload.wrapped.id]]></expression-component>
</foreach>
</batch:commit>
</batch:step>
<batch:step accept-policy="ONLY_FAILURES" name="LogFailuresStep">
<logger doc:name="Log Failure" level="INFO" message="Got Failure #[payload]"/>
</batch:step>
</batch:process-records>
<batch:on-complete>
<logger doc:name="Log Results" level="INFO" message="#[payload.loadedRecords] Loaded Records #[payload.failedRecords] Failed Records"/>
</batch:on-complete>
</batch:job>
</mule>Furthermore, you can try to modify the payload of the first record by simply referencing it using Random Access from a new Expression component outside the Foreach scope.
The Expression component should be:
<expression-component doc:name="Expression">
records[1].payload = 'New payload for the second record'
</expression-component>This only modifies the payload of the second record, and if you check your LoggerMessageProcessor for each payload, it catches something like this:
LoggerMessageProcessor: {FirstName=John, LastName=Doe, Email=john.doe@texasComp.com, Phone=096548763}
LoggerMessageProcessor: New payload for the second recordSee Also
-
Access reference details about batch processing.
-
Read about the basic anatomy of batch processing in Mule.
-
Examine the attributes you can configure for batch jobs, steps, and message processors.
-
Learn more about setting and removing record-level variables.